
Yao Luo (罗尧) is a LLM researcher at the ByteDance Seed Team. She received her Master’s degree from the National University of Singapore and her Bachelor’s degree from the Beijing University of Posts and Telecommunications.
She is dedicated to developing efficient and powerful architectures of foundation model, including large language models and large multimodal models. To this end, her research interests include sparse architectures, linear attention, long-context modeling, and model merging, among others.
We are recruiting LLM interns. If you’re interested in LLM efficiency or sparse/linear attention, feel free to contact me via Email
luoyao0323@163.comor WeChat15600307011.
🔥 News
- 2025.05: 🎉 We offer some pre-training guidelines for effective model merging!
- 2025.04: 🎉 We release Seed1.5-Thinking, a powerful reasoning model!
- 2025.01: 🎉 2 papers about long-context modeling are accepted by ICLR 2025!
📝 Publications
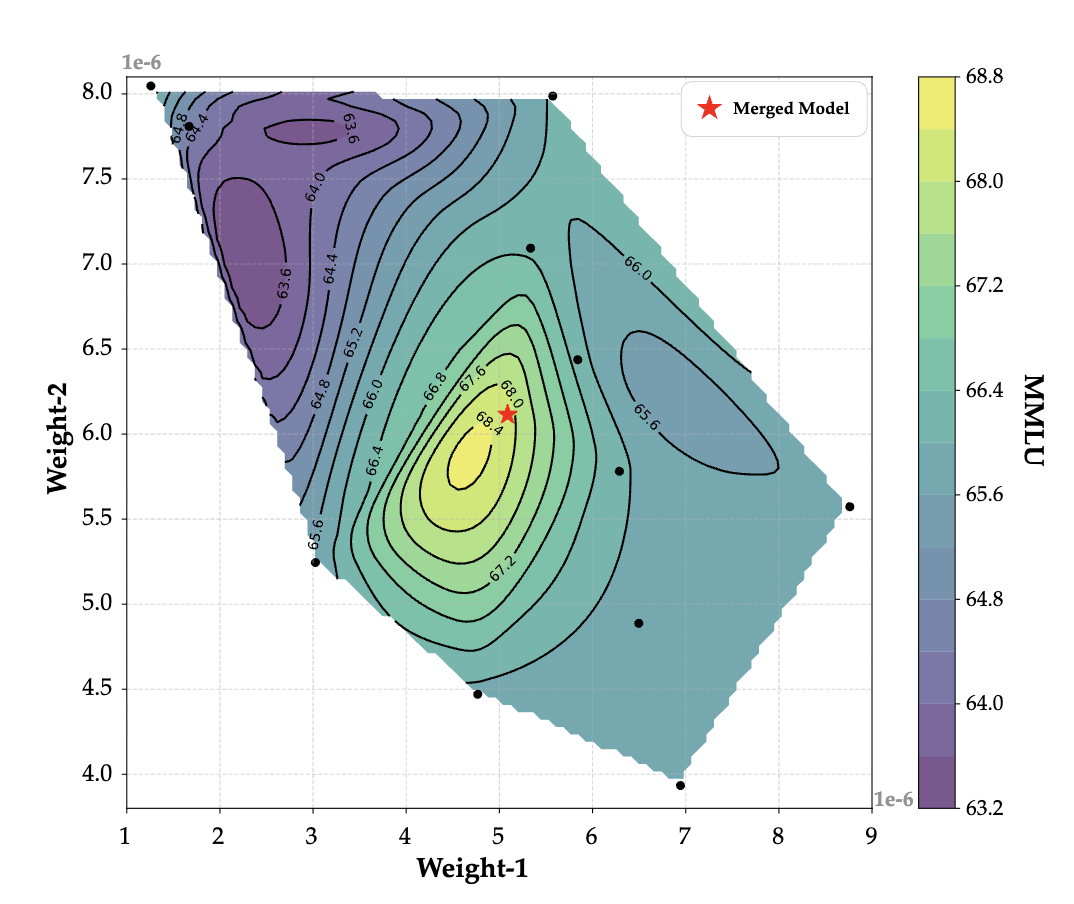
Model Merging in Pre-training of Large Language Models
ByteDance Seed
![]()
- We present a comprehensive investigation of model merging techniques during the pre-training process.
- Merging checkpoints trained with constant learning rates not only achieves significant performance improvements but also enables accurate prediction of annealing behavior.
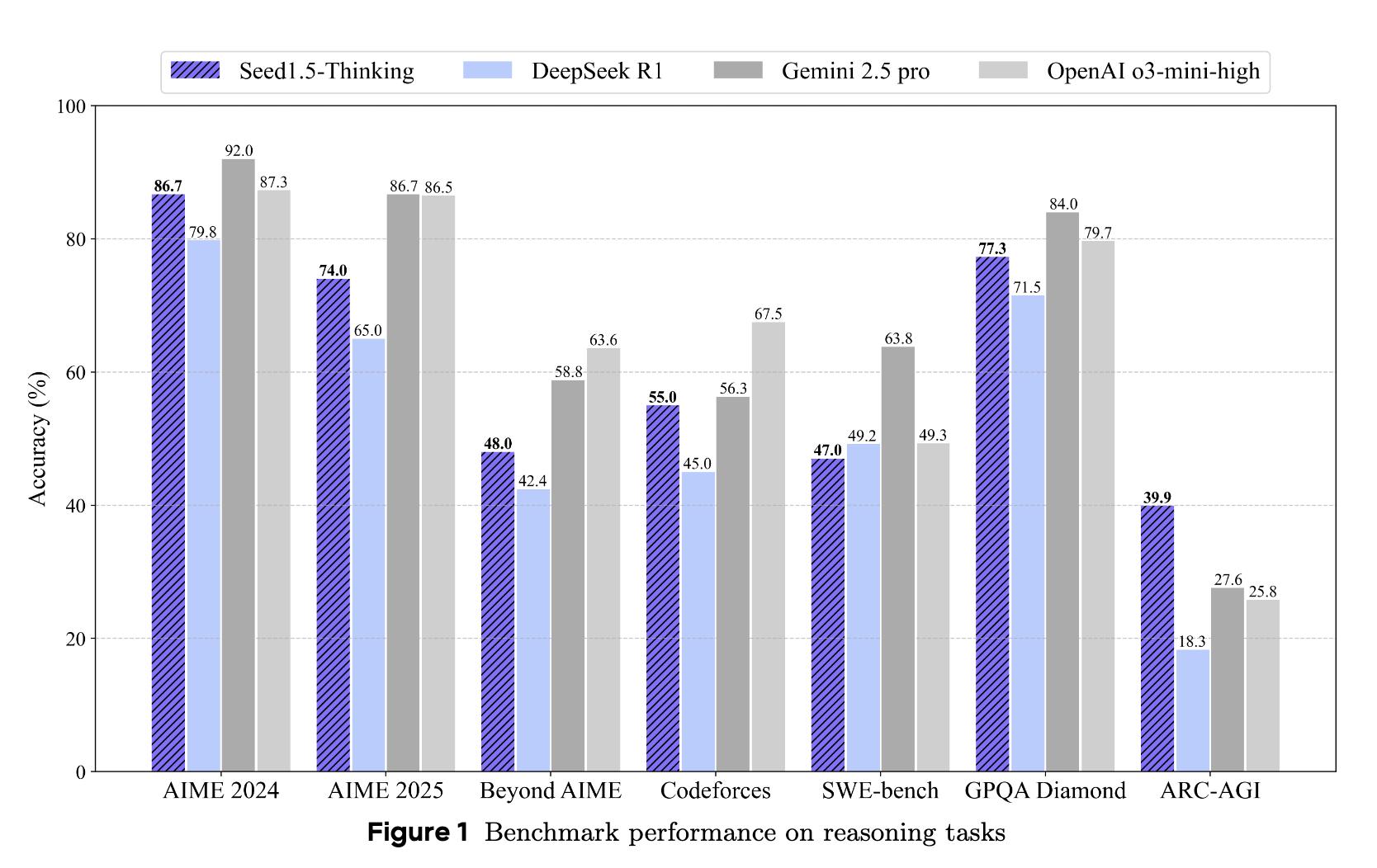
Seed1.5-Thinking: Advancing Superb Reasoning Models with Reinforcement Learning
ByteDance Seed
![]()
![]()
- Seed1.5-Thinking has achieved strong performance in both reasoning and non-reasoning tasks.
- Seed1.5-Thinking is a Mixture-of-Experts (MoE) model with a relatively small size, featuring 20B activated and 200B total parameters.
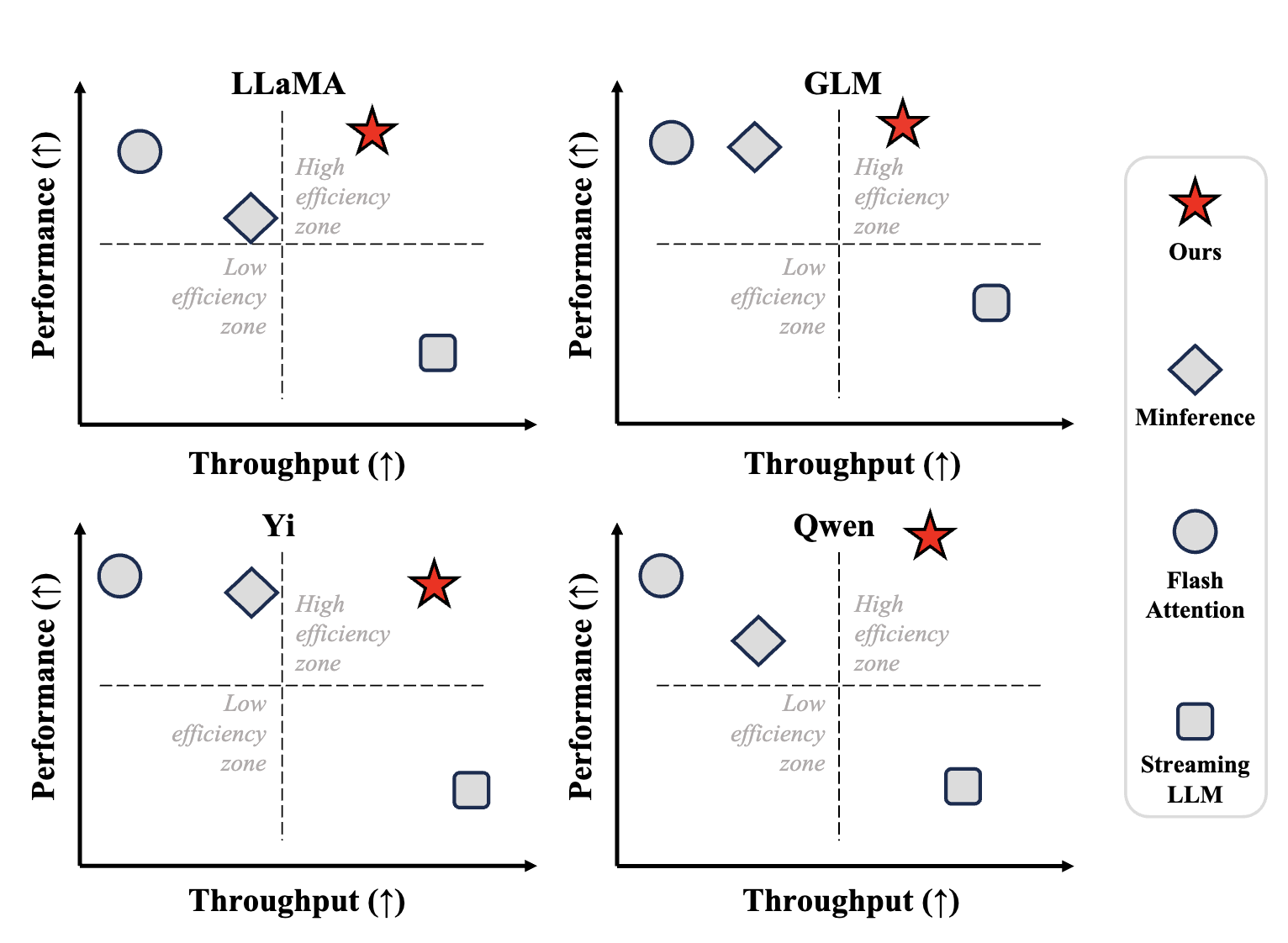
FlexPrefill: A Context-Aware Sparse Attention Mechanism for Efficient Long-Sequence Inference
Xunhao Lai, Jianqiao Lu, Yao Luo, Yiyuan Ma, Xun Zhou
![]()

- FlexPrefill is a dynamic and context-aware sparse attention mechanism that optimizes computational efficiency during long-sequence inference for LLMs.
- FlexPrefill can dynamically adjust sparse attention patterns and computational budgets in real-time based on input demands and attention head requirements.
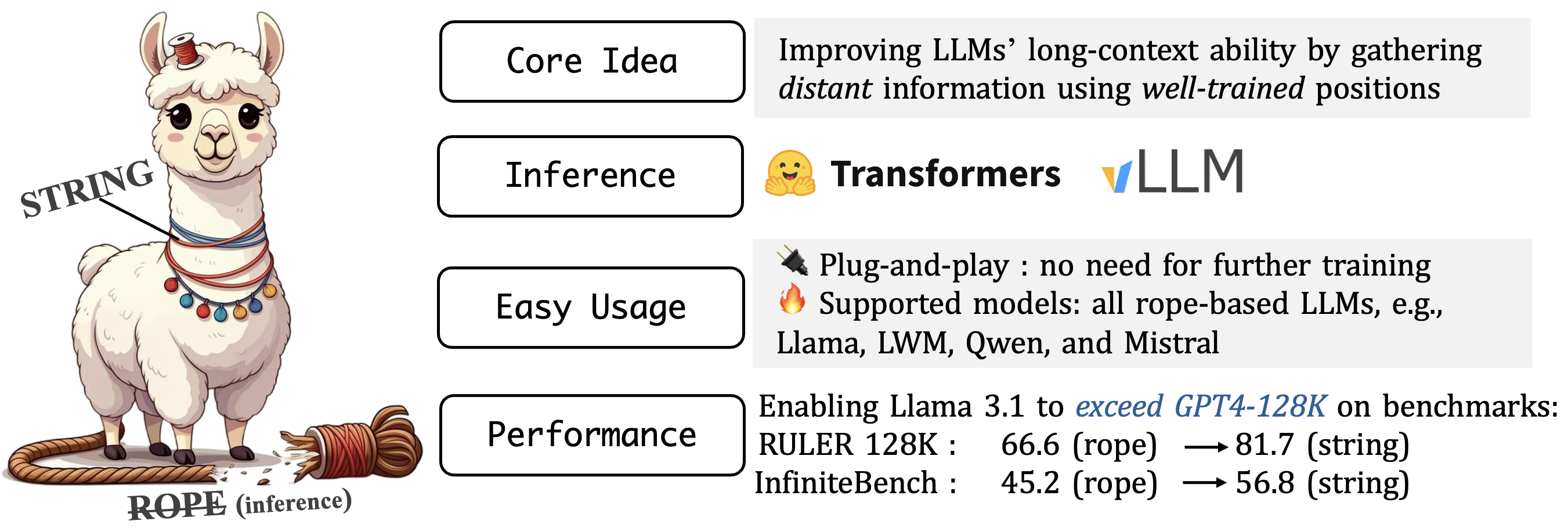
Why Does the Effective Context Length of LLMs Fall Short?
Chenxin An, Jun Zhang, Ming Zhong, Lei Li, Shansan Gong, Yao Luo, Jingjing Xu, Lingpeng Kong
![]()

- We find there is a left-skewed position frequency distribution in LLM pretraining and these infrequent positions cannot effectively model long-range dependencies.
- We propose STRING, a training-free method that does not require further training but brings significant improvements to popular RoPE-based LLMs.
📖 Experience
- 2021.10 - now, researcher at ByteDance.
- 2020.09 - 2021.07: Master’s degree. National University of Singapore.
- 2019.08 - 2019.11: Research intern. National University of Singapore.
- 2016.09 - 2020.06: Bachelor’s degree. Beijing University of Posts and Telecommunications.
